洛谷爬虫
技术向约 1.2 千字
截至目前,洛谷已经有了近两万道题目和四十余万名用户。本代码爬取了一些样本,以供后续(可能)的数据分析。
本次爬取遵守洛谷的 robots.txt 中的要求,不爬取提交记录页面。为了避免影响洛谷的正常运行,脚本只采用单线程进行爬取。
User-Agent: *
Disallow: /record
Disallow: /recordnew爬取题目信息
题目数据获取
先使用 curl 获取洛谷的题目页面:
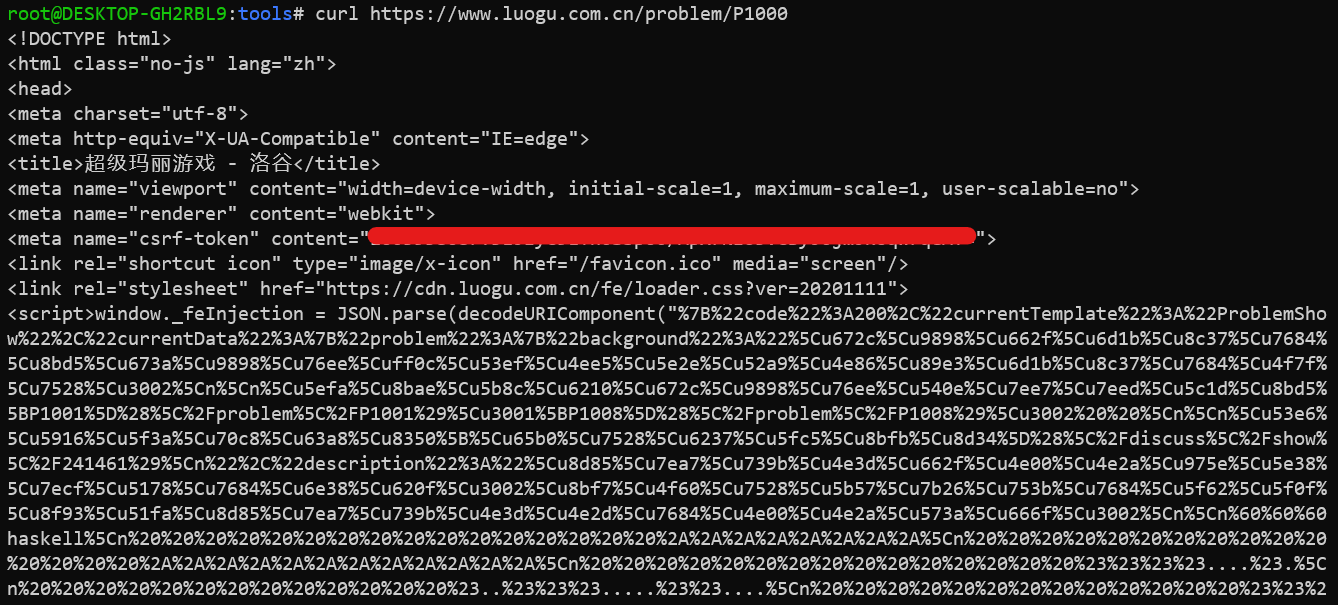
可以看出我们需要的数据都在传入给 decodeURIComponent() 函数的字符串中,正则匹配取出即可。
下面是代码实现:
#!/usr/bin/python3
# coding: utf-8
import requests
import re
import json
from urllib.parse import unquote
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 Spider/0.1"
}
def getProblemJSON(pid):
return json.loads(unquote(str(re.findall(r'decodeURIComponent\("(.*)"\)', requests.get(url="https://www.luogu.com.cn/problem/P1000", headers=headers).text)[0])))
data = getProblemJSON("P1000")
print(json.dumps(data['currentData'], sort_keys=True, indent=4))Update at 2021/02/05:
添加参数 _contentOnly=1 可以直接获取 JSON 格式的信息,无需再正则匹配。
--- a/tools/spider.py
+++ b/tools/spider.py
@@ -19,8 +19,7 @@
def getProblem(pid):
- url = f"https://www.luogu.com.cn/problem/{pid}"
- redata = re.findall(r'decodeURIComponent\("(.*)"\)',
- requests.get(url, headers=headers).text)
+ url = f"https://www.luogu.com.cn/problem/{pid}?_contentOnly=1"
+ redata = requests.get(url, headers=headers).text
if len(redata) == 0:
return { "code": 403 }
else:
- return json.loads(unquote(redata[0]))
+ return json.loads(redata)处理题目数据
这里只留下 currentData.problem 字段里面的内容即可。
#!/usr/bin/python3
# coding: utf-8
import requests
import re
import json
from urllib.parse import unquote
f = open('problems.json', 'w')
res = []
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4331.0 Safari/537.36 spider/0.1",
}
def getProblem(pid):
return json.loads(requests.get(f"https://www.luogu.com.cn/problem/{pid}?_contentOnly=1", headers=headers).text)['currentData']
for i in range(1000, 1010):
tmpdict = {}
tmpdict["pid"] = f"P{i}"
tmpdict["data"] = getProblem(f"P{i}")["problem"]
res.append(tmpdict)
# print(res)
f.write(json.dumps(res, indent=4).replace("\\t", " "))最终代码
#!/usr/bin/python3
# coding: utf-8
import requests
import json
import time
import pymongo
dbclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
luogudb = dbclient["luogu"]
dbcol = luogudb["problem"]
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4331.0 Safari/537.36 spider/0.1",
}
def getProblem(pid):
url = f"https://www.luogu.com.cn/problem/{pid}?_contentOnly=1"
redata = requests.get(url, headers=headers).text
return json.loads(redata)
for i in range(1000, 7103):
pid = f"P{i}"
if list(dbcol.find({'pid': pid})) == []:
tmpdict = {}
tmpdict["pid"] = pid
tmpdata = getProblem(pid)
if tmpdata["code"] == 200:
tmpdict["data"] = getProblem(pid)["currentData"]["problem"]
dbcol.insert_one(tmpdict)
print(f"Successfully get problem {pid}.")
time.sleep(1)
else:
print(f"Fail to get problem {pid}.")
else:
print(f"Problem {pid} is already exists.")有关于数据库读写的部分请参考下文的 数据库 部分。
爬取用户信息
结构与题目爬虫类似,故不再作代码说明。
import json
import time
import pymongo
import requests
dbclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
luogudb = dbclient["luogu"]
dbcol = luogudb["user"]
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4331.0 Safari/537.36", }
def getUser(uid):
url = f"https://www.luogu.com.cn/user/{uid}?_contentOnly=1"
redata = requests.get(url, headers=headers).text
return json.loads(redata)
for uid in range(1, 2):
if list(dbcol.find({'uid': uid})) == []:
tmpdict = {}
tmpdict["_id"] = uid
tmpdict["uid"] = uid
tmpdata = getUser(uid)
if tmpdata["code"] == 200:
tmpdict["data"] = tmpdata["currentData"]["user"]
dbcol.insert_one(tmpdict)
print(f"Successfully get user {uid}.")
time.sleep(0.5)
else:
print(f"Fail to get user {uid}.")
time.sleep(0.5)
else:
print(f"User {uid} is already exists.")数据库
搭建数据库
搭建 MongoDB 数据库只需要在 docker 里面跑一个容器,非常简便。
docker run -v /root/data/mongo:/data/db -itd --name mongo -p 27017:27017 mongo连接数据库
client = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
luogudb = dbclient["luogu"]
col = luogudb["problem"]存储数据
if list(col.find({'pid' : pid})) == []:
col.insert_one(data)
print("Success.")
else:
print("Already exists.")读取数据
print(list(col.find()))web 管理数据库
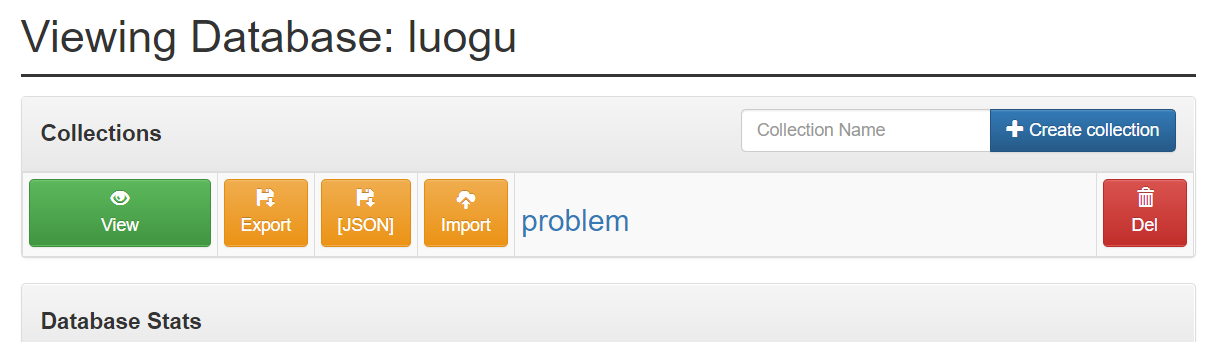
再跑一个 mongo-express 就行了。
docker run -d --name mongo-express -e ME_CONFIG_MONGODB_SERVER=host.docker.internal -p 8081:8081 mongo-express访问 ip:8081 就能看到管理界面了。
导出数据库
直接运行下方命令导出为 JSON 格式即可。
mongoexport -d luogu -c problem -o /data/db/problem.json或者点击对应数据库管理界面中的 [JSON] 按钮导出。
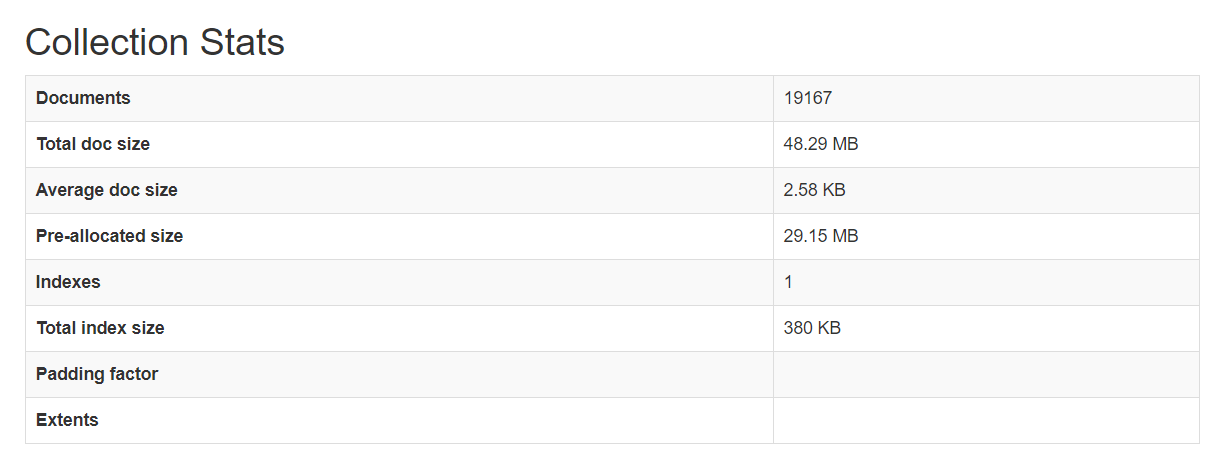
成果
断断续续爬了一个多星期,终于爬完了。
洛谷爬虫
转载或引用本文时请遵守许可协议,注明出处、不得用于商业用途!